
Word Recognition and Reading
Introduction (Top)
Reading (i.e. word recognition) is one of the most complicated visual tasks. It is the identification of symbols and translation into phonological and semantic codes (essentially the sound and meaning of the words seen). It involves deep co-operation between different brain systems.
Reading can be affected by trauma, strokes or developmental abnormalities, causing a form of alexia (difficulty reading). One form of alexia is a "letter by letter" reading, where the afflicted person can only read one letter at a time. This can be extremely time consuming as words that are 10 letters long would take twice as long to read as ones that are 5 letters long
Fixations and Saccades (Top)
The rate of information extraction during reading is controlled by both eye movement and fixations.
A saccade is a rapid movement which causes a change of fixation. When reading, 90% of our saccades are forward in direction but 10% are regressive to allow checks upon words that have been read. Each saccade traverses between 2 and 18 letters and this wide range is to incorporate the different types of font, familiarity of the text or the size of the text read.
A fixation is to maintain gaze upon an object. During reading we fixate for approximately 250 ms on a word before progressing on to the next one, but this can last longer on words that we are unfamiliar with. The actual processing of the text takes 5 ms, with the remainder of the fixation (245 ms) being used to plan the next saccade.
This explains that if words are individually presented sequentially, with the eyes fixating at a set point (eliminating the need for a saccade), it can allow for reading that is 3-4 times as fast. This is known as Rapid Serial Visual Presentation (RSVP) The concept of this idea is good, but it is a skill that would require training. It could be a good technique to incorporate with someone who has a central scotoma (say through AMD).
The number of saccades and the duration of the fixations depend on the difficulty of the text and the skill of the reader
How We Read (Top)
There are two main theories on how we are thought to read and perceive words from what we see. These theories are the bilateral projection theory and the split-fovea theory.
Bilateral Projection Theory
The bilateral projection theory suggests that the right visual field is projected on to the left visual cortex and the left visual field is projected upon the right visual cortex, but the fovea of each eye is projected to both the left and the right visual cortex (i.e. the left and right hemi-fields will overlap by 2-3° at the fovea).
This has relevance to word recognition as it suggests that whole of the centrally fixated word (falling within the fovea) is processed on each side of the brain, with no need to integrate the information between the two hemispheres.

There is evidence in the bilateral projection theory through the macular sparing in a hemianopic patient, where the whole of the foveal region can still detect form (macular sparing hemianopia seen left in diagram).
Split Fovea Theory
The split fovea theory suggests that the visual field is split down the middle such that the right half of the fovea projects to the left hemisphere and vice versa. This also has relevance to word recognition where half of the foveally fixated word projects to one hemisphere and the other half to the other hemisphere. This is demonstrated in the diagram to the right.

The two halves of the word would need to be recombined by sending information to the language dominant hemisphere (usually the left hemisphere) from the non-language-dominant hemisphere via the corpus callosum.
There is much more evidence for this theory. The more recent studies of hemaniopic patients using a scanning laser ophthalmoscope suggest that not all patients have macular sparing. If it is present then there may be functional areas within the damaged cortex. The split model can account for both foveal sparing and foveal splitting in hemaniopic patients depending on the position of the lesion, whereas extra cortex is needed in ipsilateral central vision in the bilateral model (accounting for foveal sparing but not foveal splitting in hemaniopia).
Further evidence for the split-fovea theory is that in normal patients the name wording times is dependent on right or left hemispherical dominance for language when words are fixated in different positions. For a left dominant person, the reaction times are quickest when the majority of the word is presented right of fixation as this means it is processed in the left hemisphere where the language centre is situated. This is further demonstrated below:
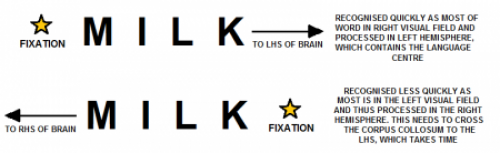
Reading times change depending on where the word is found in the visual field, due to which side of
the brain it is processed. The example shown here is of a left-hemisphere dominant person.
The processes described on the previous page would be opposite for those who are right-hemisphere dominant.
Functional MRI also demonstrates evidence of the split fovea theory. The mapped representation of different eccentricities in area V1 of normal patients found that positions to the left of fixation only presented in the right area V1 and vice versa. Therefore this is proof that only the right hemisphere is processing the left visual field.
Split-brain patients (those with a sectioned corpus collosum) find it harder to read words that need to cross the hemispheres than those that are positioned to the right of the fovea (due to processing in the LHS of the brain). This is especially true if the words are not real. However, this evidence is still under debate
Foveal vs. Peripheral Vision (Top)
The fovea is needed for clearly focused vision and reading becomes inaccurate if the subject is prevented from using the fovea. In one experiment where the fovea was masked, a sentence that read "the pretty bracelet attracted much attention" was read as "the priest brought much ammunition".
The non-foveal areas of our vision can identify general shapes and lengths of words (i.e. help in word recognition) but cannot identify each letter. Essentially we use the words to the right of fixation to guide our saccades, which therefore means that our peripheral vision is important in vision
Sentences vs. Single Words (Top)
In 1886, Cattel found that a subject can identify a word twice as quickly if it was presented in the context of a sentence. We have found that we identify letters embedded in a word quicker than when a letter is presented in a random collection of letters (a "non-word"). This is known as the word-superiority effect.
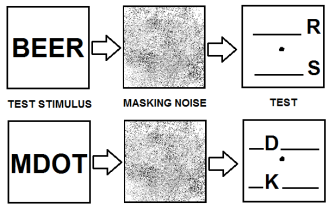
This can be seen in the Reicher-Wheeler task (shown left). It is easier to identify a letter when it formed part of a word than it is to do so from a random collection of letters.
It is worth noting that the masking noise is present in between the presentation of the test stimulus and the actual test to remove any residual after-image caused from the viewing of the test stimulus.
The word superiority effect is partly due to the prediction of redundant letters in a word (particularly the "U" after the letter "Q" in any given word). Not all are quite as obvious as this example and some can be fairly subtle.
Interestingly, it is easier to detect fair vs hair than it is to detect an F vs H. This cannot be due to prediction of the redundant letters in the word here as it is impossible to predict the letters F or H in the word ending *AIR. This can be seen in the diagram to the right. Therefore the word superiority effect makes it easier to detect letters in words over individual letter presentations.
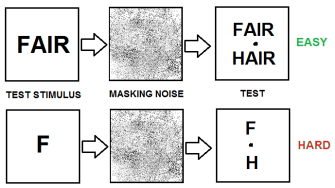
The Word Superiority Effect
A large unit (i.e. a word) will be seen much better than any of its component parts (i.e. the letters). It will also be seen much better than a random collection of letters that make a non-meaningful word. This suggests a top-down effect where meaningfulness of the word helps to identify its component letters. This may also be due to a pronounceable difference where non-words are harder to pronounce than real words. An example of this would be of "TREE" and "TVXC", where the letters in TREE are identified more easily due to the frequency we come across the word to process it.
Top-Down Processing
Familiar words, letter shapes, sentence structures and episodic knowledge (i.e. background knowledge on what is being read) are used to guide the reader and this is likely to allow us to predict the next likely word in the sentence. If text is unfamiliar, then it is harder to predict and therefore it will be read more slowly.
For example, the following sentence will likely be read slowly as the words are random and it is therefore impossible to predict the next word in the sentence:
ORANGES DISHWASHER COMPUTER SUICIDE REVISION PARANOID CHICKEN BANANA
Additionally, if a unexpected word appears in or at the end of the sentence, then reading is slowed whilst the sentence is processed. This can be seen in the sentence below:
I WOULD LIKE TO GO OUT AND DRINK A MICROWAVE
As the word "microwave" is not an expected word, it throws the reading processing down and forces the reader to double-check as it is not a predicted word.
Additionally "you dnot hvae to hvae the ltteres in the rgiht odrer to dteernmie three mnaneig" as top-down processing allows us to determine the correct words based on prediction and word shape.
The visual processing is also prone to miss letters from frequent functions when asked to detect the frequency of a specific letter. Greenberg et al. (2004) found that time spent processing these high frequency function words at the whole word level was surprisingly short, thereby enabling the fast and early use of these words to build a tentative structural frame.
In summary:
WE DON'T READ THE WORD THEN FIND THE MEANING, WE TOP-DOWN PROCESS TO HELP US FIND THE MEANINGFUL WORD.
THIS CONCLUDES THE UNIT ON WORD RECOGNITION AND READING